哈佛医学院亲测诊断准确率88%!GPT能否代替医生?
 医学热点官方号
医学热点官方号 关注
关注太长不看版
✓ GPT-3在医疗诊断准确性上接近专业医生水平,显著高于非专业人士。
✓ GPT-3在分诊准确性上低于医生,对紧急病例的识别存在不足。
✓ 在高信心水平下,GPT-3也可能给出错误判断。
随着人工智能(AI)技术的快速发展,其在医疗领域的应用已成为研究的热点。AI在医学影像诊断、病理分析、药物发现等多个方面展现出巨大潜力。然而,AI在临床诊断和分诊中的准确性和可靠性,尤其是在与医生和非专业人士的比较中的表现,尚需深入研究。Generative Pre-trained Transformer(GPT)作为一种通用AI语言模型,虽然未接受过专业医疗训练,但其在处理自然语言方面的卓越能力使其在医疗诊断领域具有潜在的应用价值。
研究设计
本研究为观察性研究,旨在比较GPT-3在48个经过验证的合成病例摘要(少于50个词,阅读难度不超过六年级水平)上的诊断和分诊准确性。病例涵盖常见(如病毒感染)和严重(如心脏病发作)疾病。对比对象包括5000名能够使用互联网查找正确选项的非专业人士,以及21位在哈佛医学院执业的医生。每个分诊类别(紧急、1天内、1周内、自我护理)有12个病例摘要。每个病例的正确诊断和分诊类别由哈佛医学院的两名普内科医生确定。研究中,GPT-3、非专业人士和医生都被要求根据病例摘要列出可能的诊断,并按可能性顺序排列。如果正确诊断出现在列出的前三位诊断中,视为正确。
分诊准确性根据人类/GPT-3所选的分诊类别是否完全符合四个分诊类别,或是否匹配二分分诊变量(紧急或1天内 vs 1周内或自我护理)确定。使用修改后的自举重采样程序估算GPT-3在给定病例摘要上的诊断和分诊信心,并通过计算校准曲线和Brier评分来检查GPT-3的信心校准情况。
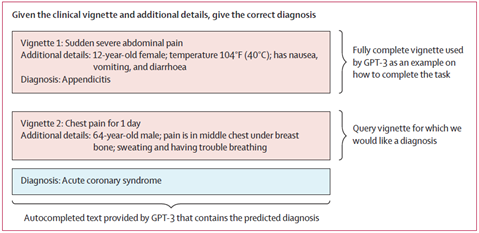 GPT-3提示词示例
GPT-3提示词示例
研究结果
1. GPT诊断准确性接近医生
在所有病例中,GPT-3在其前三诊断中正确回答的比例为88%(42/48,95% CI:75%–94%),相比之下,非专业人士为54%(2700/5000,95% CI:53%–55%),医生为96%(637/666,95% CI:94%–97%)。GPT-3的诊断准确性接近医生,且显著高于非专业人士。
2.准确性与疾病紧急程度负相关
病例紧急程度与GPT-3准确性之间存在负相关性,即随着病例紧急程度的增加,GPT-3的准确性下降。具体来说,对于自我护理病例,GPT-3的准确性为100%,而对于紧急病例,准确性下降至75%。这可能与互联网上训练数据的偏差有关。
3. 分诊准确性不足
在分诊准确性方面,GPT-3的正确率为70%(34/48, 95% CI: 57%–82%),与非专业人士的74%(3706/5000,95% CI:73%–75%)相比无显著差异,低于医生的91%(608/666,95% CI:89%–93%)。这表明GPT-3在分诊方面的表现不如医生,且在某些情况下可能存在较大的差距。
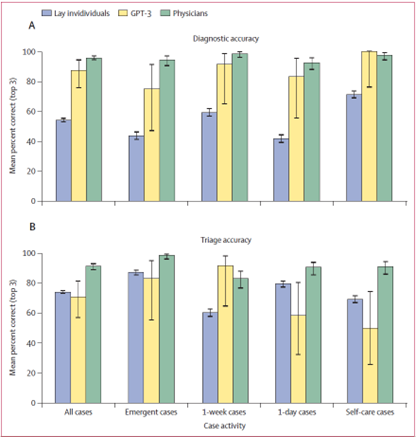 非专业人士、GPT-3及初级护理医生的诊断(A)和分诊(B)准确性
非专业人士、GPT-3及初级护理医生的诊断(A)和分诊(B)准确性
4. 模型信心与校准度情况
GPT-3在正确预测和错误预测之间的平均信心水平存在一些差异。当分诊预测正确时,模型的平均信心约为0.85,而当预测错误时,信心为0.77。总体而言,GPT-3在大多数诊断和分诊预测中表现出较高的信心,且在大多数病例中对其首位预测的信心超过50%。通过Brier评分衡量,GPT-3对其首位预测的信心在诊断(Brier评分=0.18)和分诊(Brier评分=0.22)方面均具有合理的校准度。
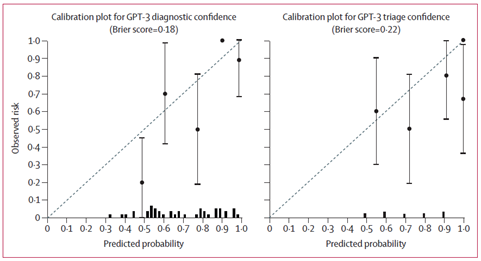 对GPT-3 在诊断和分诊中预测信心评分的校准分析
对GPT-3 在诊断和分诊中预测信心评分的校准分析
5. 分诊错误分析
GPT-3在7个案例中降低了真正紧急病例的优先级,这些案例的正确分诊级别应为「紧急或1天内」,但模型预测了较低的紧急程度。此外,模型在7个非紧急病例中过度预测了紧急程度。在处理具有持续性症状的病例,如发热、皮疹和呼吸困难时,AI低估了紧急性;而在处理局部、较轻微症状的病例,例如蜜蜂蜇伤、皮肤肿块和眼睛刺激时高估了紧急性。
讨论
本研究展示了一种通用AI语言模型(GPT-3)在医疗诊断和分诊任务中的潜力。在没有接受过专业医疗训练的情况下,GPT-3在诊断任务中表现出色,展现出了接近医生的诊断准确性和显著高于非专业人士的诊断能力。这可能归功于其在大量互联网文本上的训练,从而能够理解和生成与医疗相关的自然语言。GPT-3在分诊方面的表现不如医生,尤其在紧急病例的识别上存在不足,这可能与其训练数据的偏差或缺乏专业医疗知识有关。
GPT-3的信心水平与其预测的准确性有关,但即使在错误预测时其也表现出较高的信心,这提示了在实际应用中需要对AI模型的预测进行谨慎解读。未来但仍需进一步的研究和优化以提高其在分诊任务中的准确性。未来的研究应关注模型的改进、临床集成以及用户接受度,以确保AI技术能够在医疗领域发挥最大的价值。
参考文献
Levine DM, Tuwani R, Kompa B, et al. The diagnostic and triage accuracy of the GPT-3 artificial intelligence model: an observational study. Lancet Digit Health. 2024;6:e555-e561. doi:10.1016/S2666-7568(24)00112-0.
原创文章:方舟健客版权所有,未经许可不得转载。
 举报
举报 点赞
点赞 分享
分享